Putting the Tool to Work
What Happens If I Keep The Prompt Extremely Simple?
The Question
I wanted to know whether Perchance needs a carefully engineered prompt or whether it can still produce something interesting from a plain idea. Many casual users will not arrive with long prompt formulas. They will type a few words, press generate, and expect the system to fill in the blanks. This session began with that kind of low-effort curiosity, using a short visual idea instead of a detailed art direction.
Observation Window
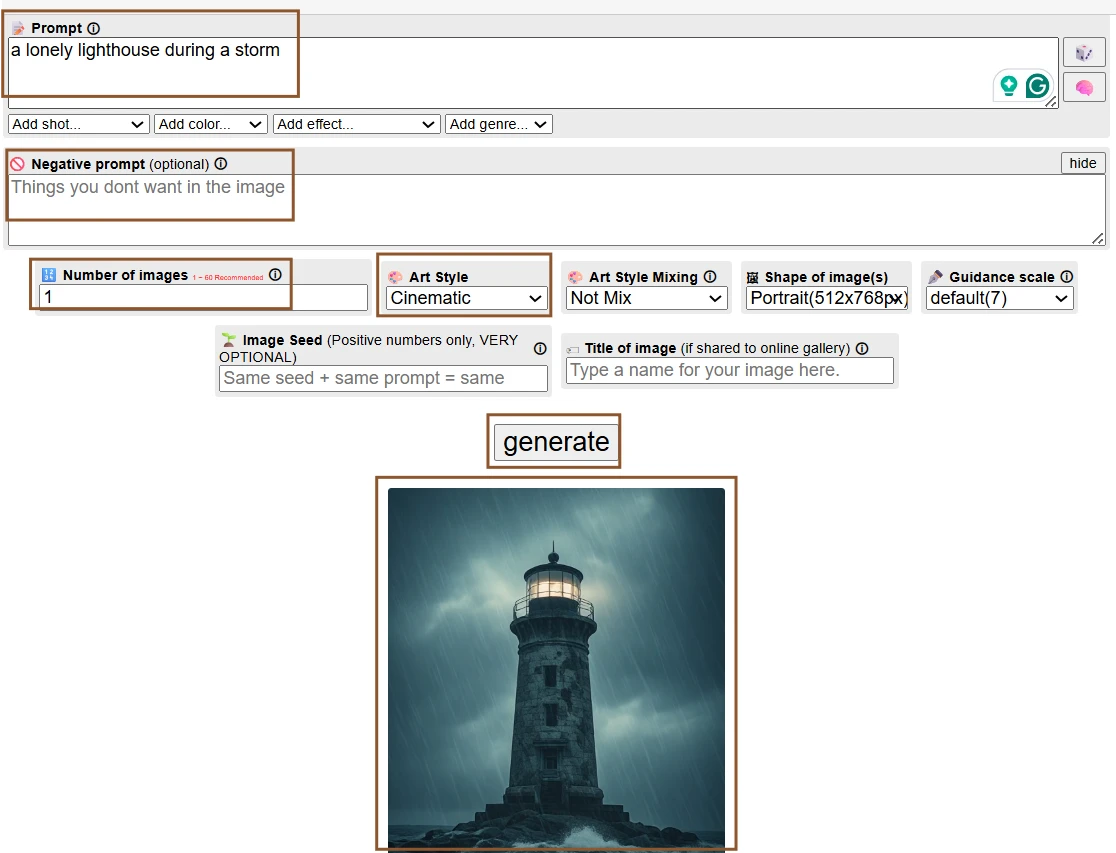
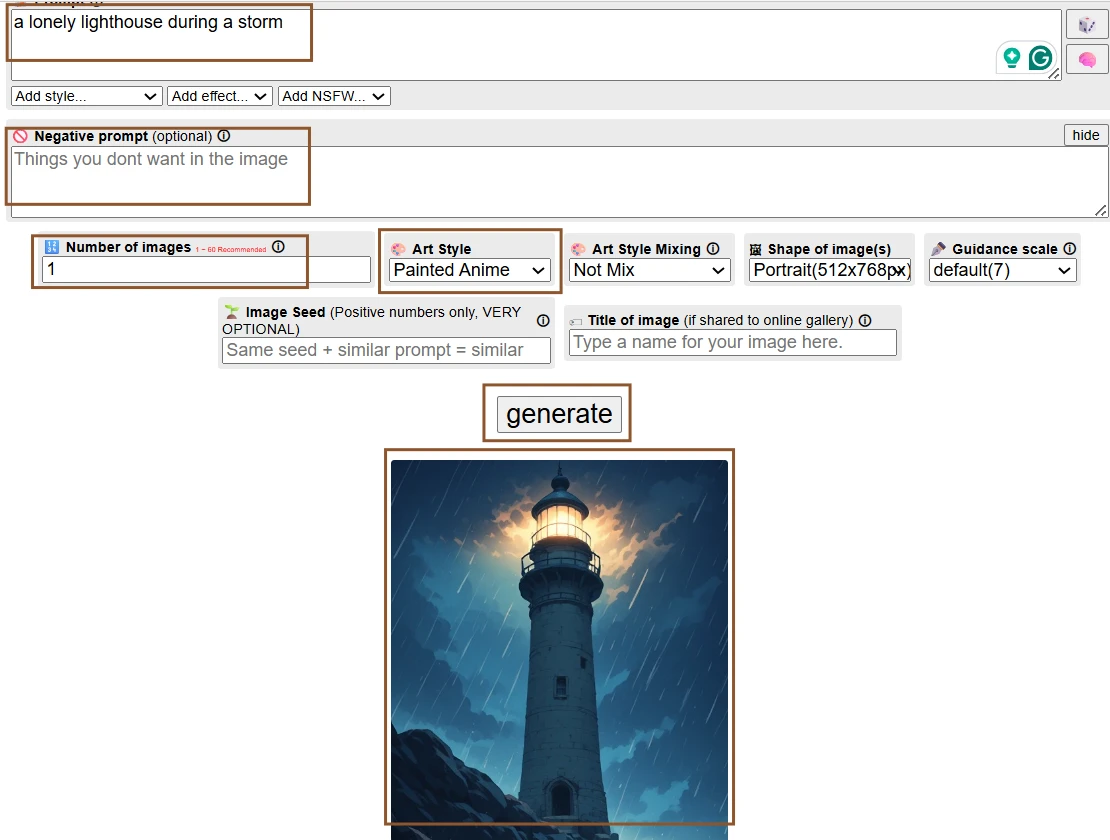
On the screen, the phrase “a lonely lighthouse during a storm” sits in the prompt box with no extra descriptive language around it. Below it, the results show a coastline scene built from very few words. The lighthouse appears as the main vertical shape, surrounded by dark sky, rough water, and cloudy atmosphere. Some outputs place the building on a cliff, while others move it closer to the sea. The images do not look identical, even though the prompt has barely changed.
Unexpected Discovery
The short prompt did not leave the image empty. Perchance seemed comfortable inventing missing visual details, especially mood, weather, and background. The interesting part was not that the lighthouse appeared, but that the tool filled the scene with enough atmosphere to feel like a complete image. At the same time, the lack of detail made the results drift. One image felt like a dramatic movie still, while another leaned closer to fantasy illustration. The platform rewarded even a simple idea, but it also reminded me that a short prompt gives the generator permission to make many decisions on its own.
If I Continued This Experiment...
I would keep the same three-word structure and try different subjects: “abandoned cinema,” “robot gardener,” “winter market.” That would show whether Perchance is equally comfortable inventing detail across architecture, characters, objects, and crowded scenes.
How Much Variety Appears When I Repeat The Same Idea?
The Question
Perchance is often talked about as a playground because it encourages repeated generation rather than careful one-shot creation. I wanted to see how wide the variation becomes when the prompt stays almost unchanged. This mattered because free, high-volume generation is only useful if repeated attempts actually give different creative options instead of minor copies of the same result.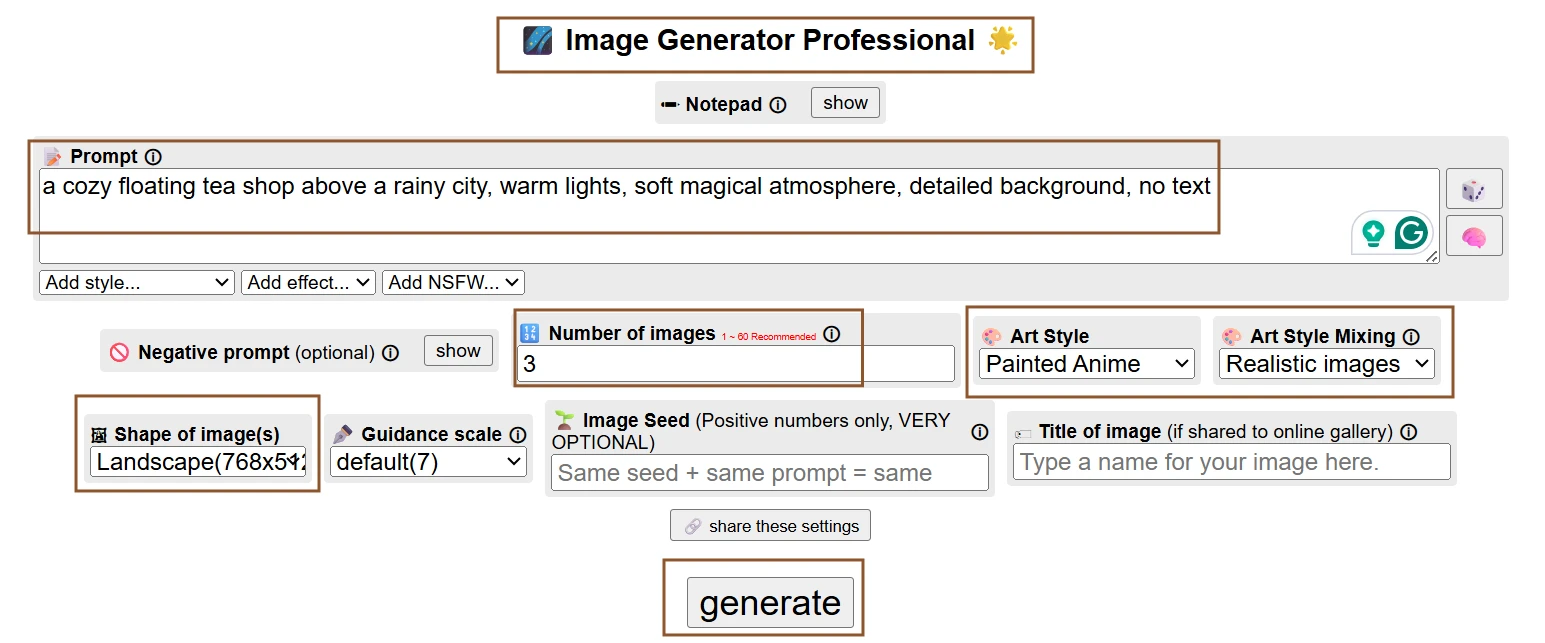

Observation Window
Several versions of the floating tea shop sit together on the page. In one image, the shop hangs like a small wooden room above the skyline. In another, it looks more like a glowing balcony with lanterns and rain streaks around it. Some versions show the city clearly below, while others bury the background in mist and warm light. The color palette stays close across the group, but the shape of the shop, the amount of rain, and the distance from the skyline change from image to image.
Unexpected Discovery
The repeated generations were not just small rearrangements. Perchance treated the same prompt like a loose creative seed rather than a fixed instruction. That made the session feel fast and exploratory. I could imagine using it for early mood-board work because the results gave several directions without needing new prompts each time. The trade-off became visible at the same moment. If I wanted the tea shop to keep a specific structure, repeated generation would not guarantee it. The platform was better at offering branches of an idea than preserving one exact design.
If I Continued This Experiment...
I would freeze the strongest image concept in writing and keep adding sharper constraints: “same shop shape,” “same angle,” “larger city below,” “no extra buildings.” That would reveal how far Perchance can move from playful variation toward controlled art direction.
Why Does Anime Feel So Natural Here?
The Question
Reviewner’s review points toward Perchance being especially useful for anime-style characters and imaginative character images. I wanted to see whether that strength appeared naturally or only with careful prompting. For this session, I chose a character concept that needed expression, costume, background, and mood, but I kept it broad enough that the generator had room to interpret the scene.
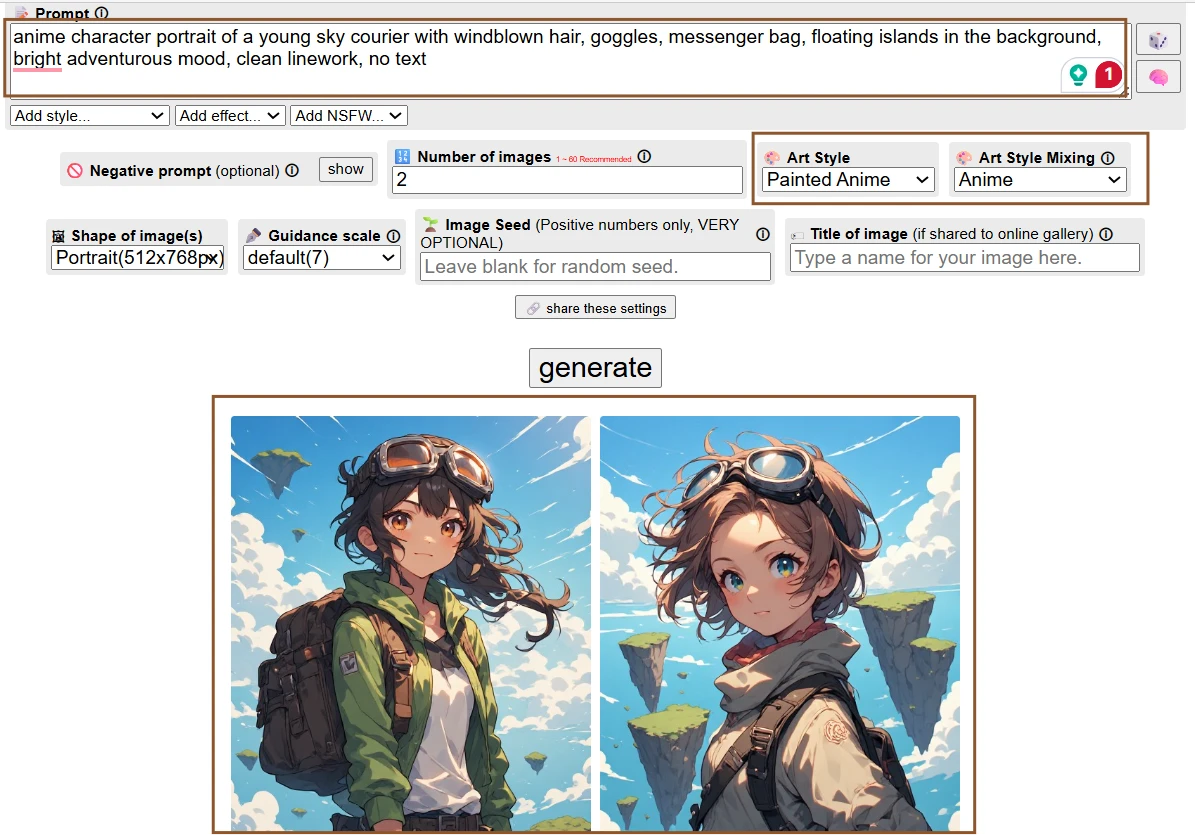
Observation Window
The selected image shows an anime-style courier facing slightly away from the viewer, with goggles, layered clothing, and a bag crossing the body. Wind moves through the hair and scarf, while floating islands sit in the distance behind the character. The background is lighter than the foreground, leaving the figure as the main focus. The outfit includes small straps and travel details, and the overall frame reads as a character concept rather than a plain portrait.
Unexpected Discovery
This session felt more fluent than the others. Perchance did not need much help understanding the character type, and the anime styling gave the image a clearer visual language. The tool seemed to know what kind of details belonged in the scene: goggles, travel gear, sky, wind, and a bright fantasy backdrop. The smaller issue was familiar AI character behavior. Some accessories appeared decorative rather than functional, and tiny costume details did not always make practical sense. Still, the image arrived with a recognizable identity quickly, which explains why casual anime creators may find the platform easy to enjoy.
If I Continued This Experiment...
I would turn the same courier into a small cast: rival courier, mechanic friend, sky-pirate captain, city guard. That would test whether Perchance can keep a shared world feeling consistent across multiple character prompts.
What Happens When A Scene Needs Story Accuracy?
The Question
A beautiful image is not the same as an accurate story image. I wanted to see what happened when the prompt included a specific narrative arrangement instead of a general mood. The question mattered because Reviewner’s review flags story alignment as one of Perchance’s weaker areas. This session asked the platform to follow a small scene with several details that needed to stay in the correct relationship.
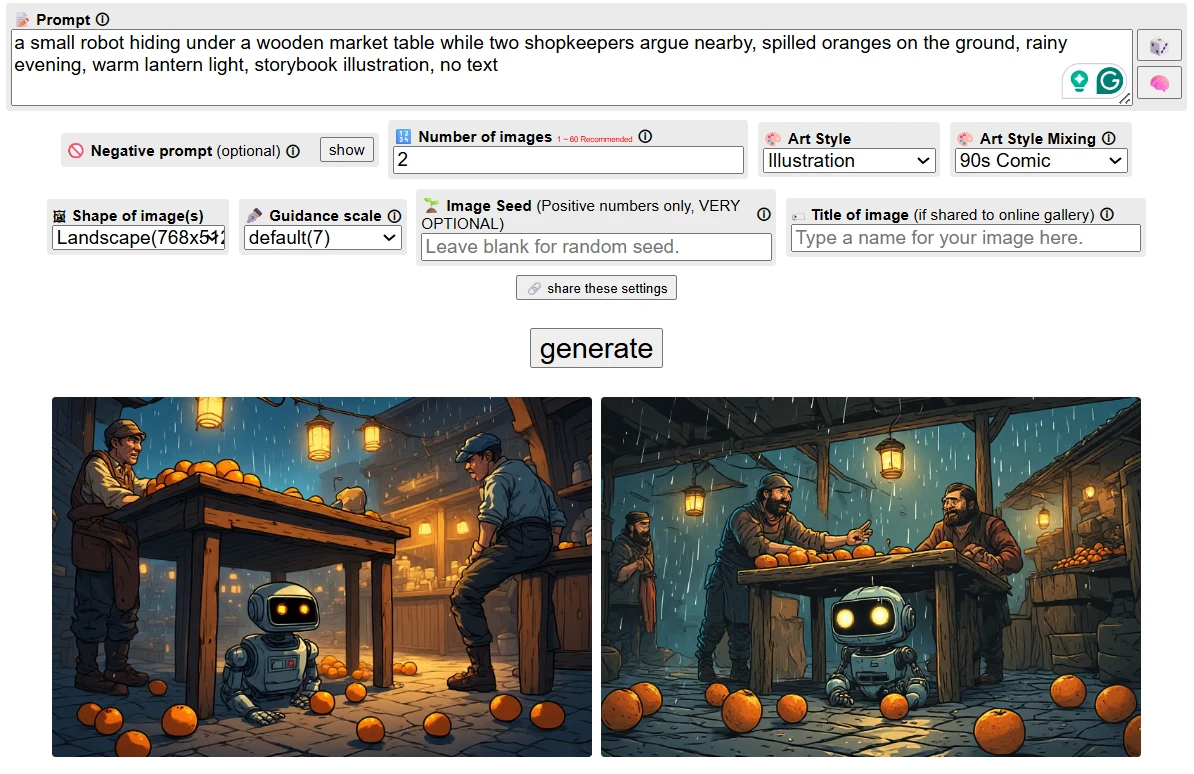
Observation Window
The scene shows a market setting at night, with warm lights, rain-darkened surfaces, and small objects scattered near the foreground. A table sits near the center of the image. A small robot figure appears close to the table area, while human figures stand nearby in the market space. Orange-colored objects are visible near the ground, though their placement and shape vary between outputs. The image contains the ingredients of the prompt, but the exact relationships between them are not equally clear in every version.
Unexpected Discovery
This was the first session where the gap between visual richness and scene accuracy became obvious. Perchance could make the market look atmospheric, but the story logic was less stable. Sometimes the robot looked beside the table instead of under it. Sometimes the shopkeepers became background figures rather than people actively arguing. The spilled oranges appeared, but not always in a way that clearly supported the scene. The tool seemed more confident with “rainy magical market” than with the exact blocking of a small narrative moment. That difference matters if someone wants illustrations to match written scenes closely.
If I Continued This Experiment...
I would simplify the scene one instruction at a time: first only the robot under the table, then add oranges, then add shopkeepers. That could show whether Perchance loses accuracy because the scene is crowded or because spatial instructions are difficult.